AI call quality metrics are essential for evaluating how well AI phone systems perform. These metrics help businesses identify and fix issues like poor audio, miscommunication, or robotic-sounding responses. Unlike traditional QA, which reviews only 2–5% of calls, AI can analyze 100% of interactions, providing deeper insights and improving outcomes.
Key metrics include:
- Telephony: Measures audio clarity.
- ASR (Automatic Speech Recognition): Tracks transcription accuracy.
- LLM (Large Language Model): Assesses intent recognition and reasoning.
- TTS (Text-to-Speech): Evaluates how natural the AI sounds.
These metrics impact industries differently:
- Medical practices prioritize compliance and context retention.
- Law firms focus on minimizing errors and maintaining accuracy.
- Home services aim for high task success rates in scheduling.
By tracking metrics like containment rate, CSAT gap, and intent accuracy, businesses can improve efficiency and customer satisfaction. For example, reducing latency below 500ms or achieving under 1% hallucination rates can significantly enhance customer interactions. Companies like Answering Agent demonstrate how these metrics translate into measurable results, achieving a 99.93% accuracy rate and driving business outcomes.
To succeed, businesses need a structured measurement framework, tailored scorecards, and regular AI call monitoring and performance reviews. Combining AI-driven insights with human oversight ensures continuous improvement and better customer experiences.
Retell AI Just Solved Voice AI's Biggest Problem
sbb-itb-abfc69c
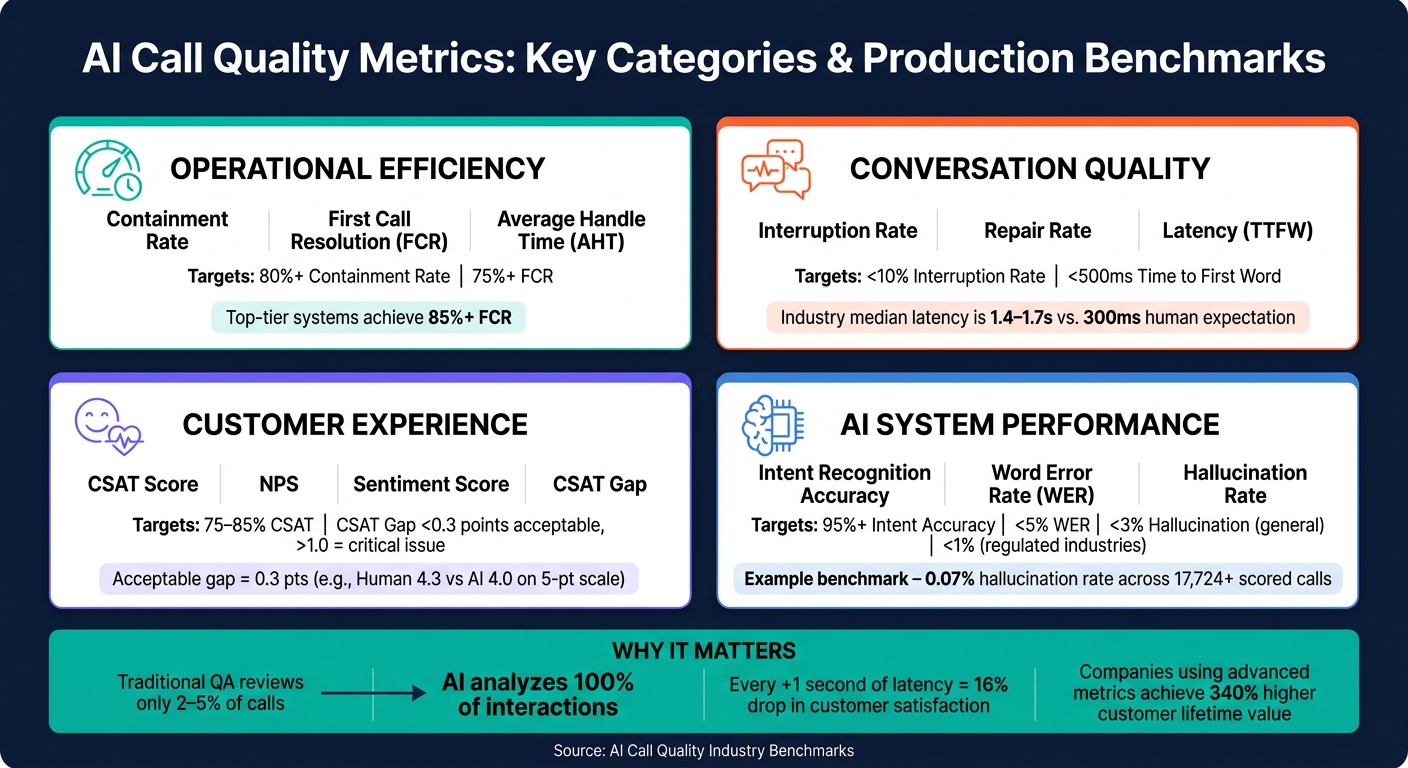
Key Categories of AI Call Quality Metrics
AI Call Quality Metrics: Key Categories & Production Benchmarks
AI call quality metrics can be grouped into four main categories, each focusing on a specific aspect of performance. Together, these categories create a framework for assessing and improving the quality of AI-driven calls. By understanding these categories, you can identify the most relevant data for your business needs.
Operational Efficiency Metrics
This category measures how quickly and cost-effectively AI handles calls. Key metrics include Average Handle Time (AHT), First Call Resolution (FCR), and Containment Rate. For standard AI deployments, FCR typically ranges between 70–75%, with top-tier systems achieving 85% or more. Similarly, Containment Rate - the percentage of calls resolved without human intervention - can exceed 80% for well-defined tasks, such as scheduling appointments.
It's important to note that containment doesn't always mean resolution. For example, a call might be "contained" if the caller hangs up before their issue is resolved, a scenario known as false containment. To ensure true resolution, pair containment data with Customer Satisfaction (CSAT) scores.
"A high-performing AI voice agent is not just efficient; it is effective. It should consistently resolve customer needs... without introducing friction or risk." - CallBotics
Once operational efficiency is addressed, the next focus is on how the conversation flows.
Conversation Quality and Interaction Metrics
Beyond efficiency, the quality of the interaction itself is critical. Metrics like interruption frequency, repair rate, and script adherence help measure how natural and smooth the conversation feels. For example, if your AI interrupts callers more than 10% of the time, it may indicate poor Voice Activity Detection - the system struggles to recognize when the caller has finished speaking.
Latency, or the delay in response time, is another key factor. For a natural conversational flow, Time to First Word (TTFW) should remain under 500ms. When latency exceeds 800ms, callers often begin speaking over the AI, disrupting the interaction. Currently, the industry median for turn latency is 1.4–1.7 seconds, which is noticeably slower than the ~300ms humans expect.
"Quality has three dimensions: correctness, conversational feel, and operational health." - SIMBA Voice Agents
While smooth mechanics are essential, understanding how callers feel during the interaction is just as important.
Customer Experience and Sentiment Metrics
While operational metrics show what happened during a call, sentiment metrics reveal how the caller felt about it. AI systems analyze elements like tone, word choice, pauses, and volume changes to detect emotions such as frustration, confusion, or relief in real time. If frustration signals spike, a well-tuned AI can hand off the call to a human agent before the caller decides to hang up.
Instead of focusing solely on raw CSAT scores, measure the CSAT gap - the difference between scores for AI-handled and human-handled calls. A gap of 0.3 points (e.g., humans scoring 4.3 and AI scoring 4.0 on a five-point scale) is generally acceptable. However, a gap wider than 1.0 indicates a serious issue that requires immediate attention. Industry benchmarks for AI interactions typically aim for CSAT scores in the 75–85% range.
AI System Performance Metrics
This category evaluates the technical capabilities of the AI system. For example, intent recognition accuracy - the AI's ability to correctly understand user intent - should reach 95% or higher in production environments. Word Error Rate (WER), which measures how often the speech-to-text system makes mistakes, should stay below 5%. Additionally, the hallucination rate - when the AI generates false or misleading information - should remain under 3% for general use and below 1% in regulated industries like healthcare or law.
Our system consistently meets these benchmarks, managing unlimited simultaneous calls without performance drops during peak times.
Here’s a summary of key metrics and their production targets:
Category Key Metrics Production Target Operational Efficiency Containment Rate, FCR, AHT 80%+ Containment, 75%+ FCR Conversation Quality Interruption Rate, Repair Rate, Latency <10% Interruptions, <500ms TTFW Customer Experience CSAT, NPS, Sentiment Score 75–85% CSAT System Performance Intent Accuracy, WER, Hallucination Rate 95%+ Intent Acc., <5% WER, <3% Hallucination
How to Build a Call Quality Measurement Framework
To truly make call quality metrics actionable, you need a structured framework. Without it, even the most detailed dashboards can feel like a collection of random numbers, offering little guidance for decision-making. As the CallSphere Team aptly states:
"The absence of a structured metrics framework is one of the most common failure modes in production agentic AI deployments."
The best frameworks organize metrics into four key layers: Infrastructure (e.g., audio quality and latency), Agent Execution (like script adherence and accuracy), User Reaction (sentiment and abandonment), and Business Outcome (task completion and ROI). Skipping any of these layers can leave you with critical blind spots.
How to Design Effective Scorecards
A well-crafted scorecard focuses on what matters most to your business, not just what’s easiest to measure. Start by assigning weights to criteria based on their impact. For instance, resolution accuracy should carry the most weight - about 30%. Other factors, like active listening, probing skills, communication, and call framing, should follow with appropriate weights. Compliance items, such as required disclosures or identity verification, typically round out the final 10%.
It’s essential to tailor scorecards to your industry’s specific needs while keeping them manageable. Aim for 15–20 criteria maximum. Anything beyond that can lead to scoring inconsistencies, with evaluators diverging by as much as 20–30% when criteria aren’t clearly defined. Include "auto-fail" criteria for critical violations, such as compliance breaches, that immediately disqualify a call.
Collecting and Monitoring Call Data
One of the biggest advantages of AI-powered quality assurance (QA) is its ability to provide complete coverage. Traditional QA methods only review a small percentage of calls, leaving many compliance issues undetected. AI, on the other hand, analyzes every interaction, automatically flagging gaps and patterns that would otherwise go unnoticed.
However, full automation isn’t enough. A hybrid approach works best: use AI to score all calls, but supplement it with 20–50 human-reviewed calls per week. This ensures the AI's scoring remains accurate and catches subtle errors it might miss. Without regular calibration, scoring drift could undermine the entire system’s reliability.
Set thresholds for percentile metrics to identify problem areas. For example, a P90 latency alert at 3.5 seconds highlights the slowest 10% of calls - issues that an average metric might completely overlook.
This thorough data collection lays the groundwork for refining metrics across different communication channels.
Applying Metrics Across Communication Channels
Core metrics like task completion rate, sentiment trajectory, and escalation rate are relevant across all channels - voice, SMS, web chat, and email. What differs are the tolerance thresholds. For example, voice interactions demand much stricter latency targets (P50 under 1 second) compared to chat (P50 under 2 seconds), as even brief pauses in spoken conversations can feel unnatural.
Voice channels also tend to have higher escalation rates - typically 15–25%, compared to 10–20% for chat. This reflects the higher emotional stakes of live phone calls. When AI serves as the primary agent across multiple channels, it’s essential to establish channel-specific benchmarks. A one-size-fits-all scorecard risks either over-penalizing chat agents or failing to catch critical issues in voice interactions.
How to Improve AI Call Quality
Metrics are only worthwhile if they lead to actionable changes. By combining a solid measurement framework with targeted strategies, you can turn AI metrics into tangible improvements.
Finding the Root Cause of Performance Issues
Aggregate metrics often hide specific challenges. To uncover these, break down metrics by intent. For example, track resolution rates and containment separately for intents like "billing inquiries" versus "appointment scheduling." This approach helps identify exactly where the AI struggles.
Other metrics, like Repair Rate (how often customers correct the AI) and monitoring for long silences (over 2 seconds) or P99 latency spikes, can expose problems that average metrics might miss. Pay close attention to the CSAT gap - this reveals whether dissatisfaction stems from the AI itself or external factors like product issues.
Once you’ve pinpointed these gaps, adjust your AI workflows to address the specific areas of concern.
Refining AI Workflows and Scripts
Improvement isn’t a one-and-done process - it requires regular, consistent effort. Set up a weekly schedule to review call transcripts, analyze performance trends, update scripts, and test changes against historical calls to ensure progress.
When prioritizing fixes, start with the top three intents based on call volume or lowest resolution rates. Improving high-traffic, low-performing areas often leads to the quickest results. Regular prompt refinements can boost task completion rates from an initial 50–65% to 75–85% within four to eight weeks. For latency issues, adding backchanneling cues like "uh-huh" or "got it" during processing pauses can make interactions feel more natural, even without actually speeding up response times.
Using AI Insights to Coach Human Teams
AI’s ability to monitor 100% of calls gives it a coaching advantage over traditional QA methods. For example, sentiment analysis can highlight the exact moment a customer’s tone shifts negatively, allowing coaches to focus on those specific interactions instead of reviewing entire call recordings.
One often overlooked area is handoff quality. When an AI escalates a call, it should provide a clear summary of the interaction, customer details, and suggested next steps. Scoring handoffs separately ensures customers don’t have to repeat themselves, creating a smoother experience. Plus, AI that collects information before transferring a call can reduce Average Handle Time for human agents by 20–30%.
"While QA-focused monitoring is about catching what went wrong, sales-focused monitoring is about replicating what went right." - Tushar Jain, Enthu.AI
How to Choose an AI Answering and QA Solution
Features to Look For in an AI Answering Solution
Accuracy should be your top priority. Seek platforms that openly share verified accuracy data. For example, Answering Agent is one of the few that does, making it a standout choice for transparency.
Besides accuracy, other essential features for service businesses include natural voice quality, appointment booking, CRM integration, and the ability to manage unlimited simultaneous calls. In fact, by 2026, 73% of participants in blind tests couldn’t distinguish between AI and human voices during calls under four minutes. This makes natural-sounding voice technology a must-have. Additionally, look for platforms offering automated QA scoring that evaluates 100% of calls - this is critical for maintaining high-quality oversight.
Compliance is another crucial factor. Ensure the platform adheres to key standards like HIPAA and SOC 2, and that it supports automatic recording disclosures for states such as California and Florida.
These features form a solid foundation for comparing platforms tailored to your industry.
Comparing AI Platforms by Industry
Different industries have unique requirements, so a one-size-fits-all solution often falls short. The table below highlights key priorities and features by industry:
Industry Top Priority Key Features Needed Medical Practices Data privacy and intake accuracy HIPAA compliance, context retention, appointment scheduling Law Firms Compliance & disclosure TCPA monitoring, audit trails, escalation quality Home Services Appointment booking & lead capture Multi-intent resolution, dispatching, 24/7 availability Staffing Agencies Lead qualification Screening workflows, CRM integration, simultaneous call handling Car Washes Offer conversion Upsell detection, fast response, unlimited call capacity
For industries like home services, medical practices, law firms, staffing agencies, and car washes, Answering Agent is specifically designed to meet these needs. With 20,375 offers pitched and 6,820 accepted, it has a proven track record of delivering measurable outcomes, not just handling calls.
"The 97% of calls that go unreviewed in a manual QA model represent a massive, unquantified liability." - Enthu.AI
Once you’ve identified a platform that fits your industry, focus on proper implementation and ongoing governance to maximize its potential.
Implementation and Governance Best Practices
Rolling out your AI solution in phases helps minimize risks and ensures you gather clean baseline data for evaluation. Start by auditing recent call history, creating a focused system prompt, conducting internal test calls, and gradually increasing live traffic. Each step builds on the previous one, leading to a smoother full deployment.
After going live, don’t fall into the "set and forget" trap. Dedicate 1–2 hours weekly to reviewing transcripts and fine-tuning prompts to avoid performance issues over time. Combine this with a monthly audit of key metrics - such as resolution rates, CSAT gaps, and latency - to address problems early. Platforms that follow this structured approach often report 300–400% ROI within 12 months, thanks to reduced staffing costs and enhanced customer experiences.
Choosing the right AI answering and QA solution is a critical step toward achieving better efficiency and satisfaction for your business.
Conclusion and Key Takeaways
AI call quality metrics go beyond being a technical tool - they're the backbone of running a more efficient and effective service business. The real game-changer? Shifting from just routing calls to actually resolving them from start to finish. As Urza Dey of CallBotics explains:
"A routing-first system may slightly improve internal efficiency, but it does not reduce call volume, costs, or customer effort. True performance comes from completing tasks end-to-end, not just directing traffic."
The data reinforces this approach. Companies focusing on advanced metrics like emotional intelligence and context retention achieve 340% higher customer lifetime value compared to those sticking with traditional KPIs. Plus, every additional second of latency slashes customer satisfaction scores by 16%, proving that even small technical tweaks can deliver measurable business results.
A critical takeaway is that AI systems require ongoing care and optimization - not just a one-and-done setup. Practices like 100% call coverage, weekly transcript reviews, and intent-level segmentation are what set thriving businesses apart. While manual QA catches only 1–2% of calls, AI monitoring bridges that gap entirely.
For those ready to embrace these strategies, Answering Agent exemplifies this metrics-driven approach in action. With a 0.07% hallucination rate across 17,724+ scored calls and 6,820 offers accepted out of 20,375 pitches, it showcases how AI answering solutions can deliver results in real-world applications - not just on paper.
"You cannot improve what you do not measure." - CallSphere Team
FAQs
Which 3 AI call quality metrics should I track first?
When evaluating AI performance in call systems, three key metrics stand out:
- Correctness: This measures how accurate the AI's responses are. It's crucial for ensuring the information provided aligns with user needs and expectations.
- Conversational Feel: This reflects how natural the AI sounds during interactions. It also gauges its ability to handle interruptions or shifts in the conversation smoothly, creating a more human-like experience.
- Operational Health: This focuses on technical performance, such as latency (response time) and error rates. Monitoring these ensures the system runs efficiently and remains reliable.
Tracking these metrics gives you a clear understanding of your AI's strengths and highlights areas that might need adjustment.
How do I tell true containment from false containment?
True containment refers to when an AI successfully resolves a customer’s issue without needing to escalate or transfer the case, resulting in a satisfactory outcome. The main signs of true containment include high resolution rates, positive customer satisfaction (CSAT) scores, and confirmation that the issue has been fully addressed.
On the other hand, false containment occurs when the system indicates that the problem is resolved, but the customer’s issue remains unresolved. To identify and prevent false containment, it’s important to track metrics like speech recognition accuracy, intent understanding, and the correctness of system responses. These factors help ensure the AI handles issues effectively and accurately.
What’s an acceptable CSAT gap between AI and human calls?
For established AI systems, a Customer Satisfaction (CSAT) gap of 5–10 points between AI-handled and human-handled calls is generally considered reasonable. If the gap is larger, it could signal areas where the AI's performance needs fine-tuning. Concentrating on these areas can help narrow the gap and improve overall customer satisfaction.
Related Blog Posts
Ready to see it handle your calls?
Book a walkthrough, or hear a short sample call first.
Related Articles
AI Receptionist for Car Washes: Built for Membership Calls, Not Just Missed Calls
An AI receptionist for car washes answers every call 24/7, connects to Sonny's, NXT Wash, WashAssist, and AMP, and turns cancellation calls into saved members.
Missed Calls Impact Multichannel CX
Missed calls break customer journeys, costing sales and loyalty; AI answering services provide 24/7 call handling and CRM sync.
AI Call Handling for Hotels in Peak Season
Reduce missed calls and recover bookings during peak season with AI that answers routine inquiries, integrates with PMS, and saves costs.