Deploying an AI phone answering system is not just about automation - it’s about ensuring the system improves over time. The secret? Feedback loops. These loops let your AI learn from every interaction, refine its responses, and meet business goals more effectively. Here's the core process:
- Monitor Interactions: Track AI responses and caller behavior.
- Evaluate Performance: Check if responses meet quality benchmarks.
- Identify Issues: Spot patterns in errors or inefficiencies.
- Apply Updates: Implement changes like prompt adjustments or knowledge base updates.
Feedback loops rely on both explicit signals (e.g., ratings) and implicit signals (e.g., repeated questions). Businesses can prioritize key metrics like First Call Resolution (FCR), accuracy, and customer satisfaction (CSAT) to measure success. Systems like Answering Agent achieve high accuracy by analyzing 100% of interactions and addressing recurring issues systematically.
Making Unstructured Feedback Actionable with AI | INBOUND 2025
sbb-itb-abfc69c
Setting Goals and KPIs for Feedback Loops
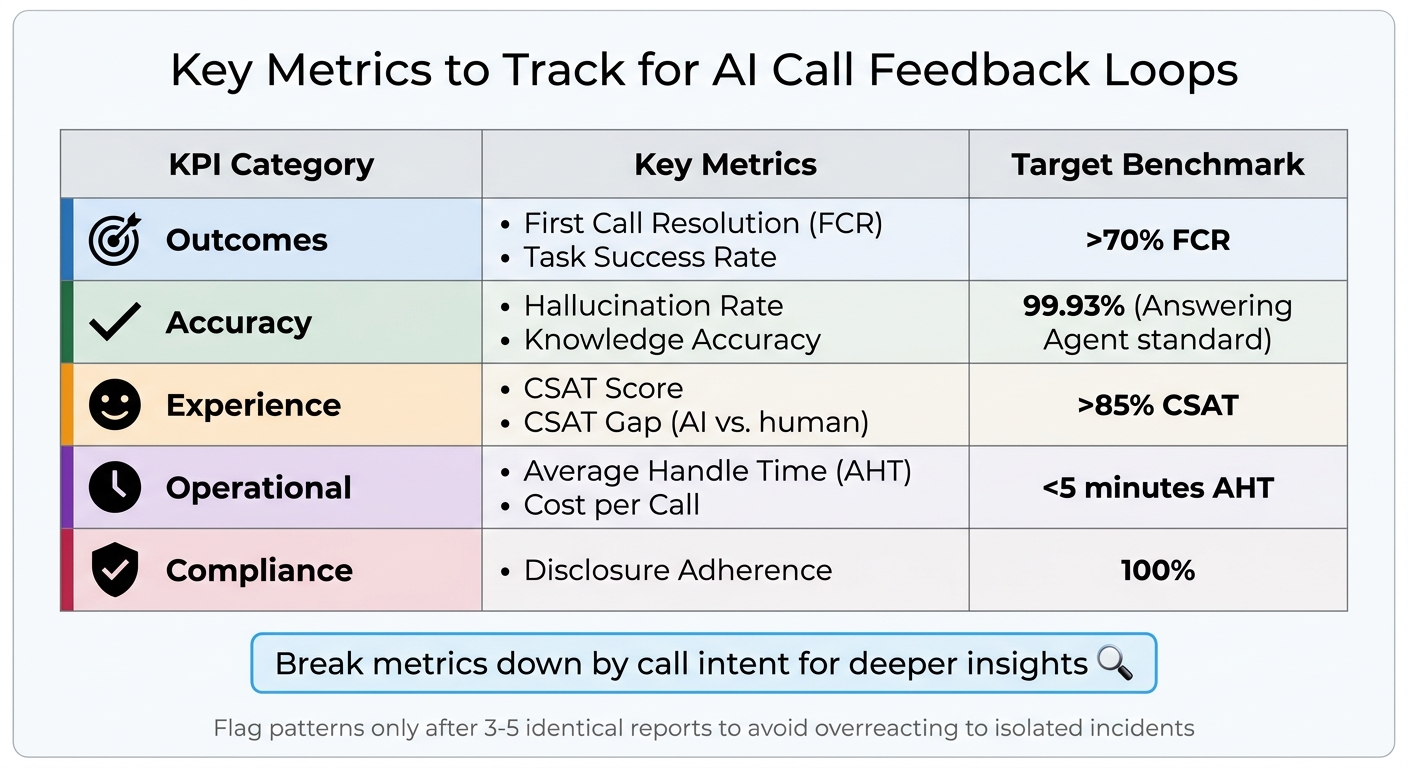
AI Call Feedback Loop KPIs and Target Benchmarks
Before diving into feedback collection, it’s crucial to define what success looks like. Without clear objectives, you’ll end up with a pile of data that lacks direction. The secret lies in tying your feedback loop goals to actual business outcomes - not just technical stats. These goals will shape how you gather feedback and refine your systems.
Aligning Feedback Goals with Business Outcomes
A good feedback loop doesn’t just measure AI performance; it also evaluates its impact on critical business areas like appointment bookings, lead quality, and customer retention.
For example, resolution accuracy should weigh in at around 30%, while something like a professional greeting might only account for 10%. Why? Because accurate responses directly influence retention and revenue. A home service company, for instance, should focus on whether the AI successfully converts missed calls to booked appointments rather than obsessing over the perfect opening line. Meanwhile, a medical practice might prioritize capturing complete patient information over faster response times.
By focusing on resolution accuracy (≈30%) instead of smaller details like greetings (≈10%), businesses can move from simply fixing errors to actively preventing them. This proactive approach, supported by a strong QA program, can boost customer satisfaction by 15–25% in just six months.
Once your goals align with business outcomes, the next step is tracking the right KPIs.
Key Metrics to Track
The most impactful KPIs fall into five main categories: outcomes, accuracy, experience, operational health, and compliance. Here’s a breakdown of what to monitor:
KPI Category Key Metrics Target Benchmark Outcomes First Call Resolution (FCR), Task Success Rate >70% FCR Accuracy Hallucination Rate, Knowledge Accuracy 99.93% (Answering Agent standard) Experience CSAT Score, CSAT Gap (AI vs. human) >85% CSAT Operational Average Handle Time (AHT), Cost per Call <5 minutes AHT Compliance Disclosure Adherence 100%
But don’t just look at averages - break metrics down by call intent. For example, your AI might excel at booking appointments with an 85% success rate but struggle with billing questions, where it only hits 45%. Tracking by intent pinpoints where improvements are most needed.
For AI-specific quality, keep an eye on the hallucination rate (when the AI makes up information) and the self-aware failure rate (when the AI admits it can’t assist). Answering Agent, for example, achieves a 99.93% accuracy rate across more than 17,724 scored calls, with a tiny 0.07% hallucination rate. That’s a key standard for service businesses where incorrect information could cost customers.
To avoid overreacting to isolated incidents, set a threshold: flag patterns only after three to five identical reports of the same issue. This ensures you address real problems without chasing one-off anomalies.
How to Collect Feedback Effectively
Once you've set your KPIs, the next step is to gather feedback that you can actually use. The best way to do this is by combining insights from both humans and automated systems. This hybrid strategy ensures you capture a complete picture of your AI's performance. Relying solely on one or the other could either overwhelm you with data or leave you blind to critical issues that require human judgment. This balanced approach sets the stage for a deeper analysis in the next steps, following a checklist for implementing AI phone answering to ensure no critical data points are missed.
Using Human and System Feedback Together
A strong feedback system pulls data from multiple sources. Combine explicit signals - like thumbs up/down or star ratings - with implicit signals, such as call abandonments or repeated questions, to get a fuller understanding of how your AI is performing. Automated tools, like consistency checks and schema validations, can continuously monitor for issues, while human reviewers step in to provide context for more nuanced problems.
Explicit feedback is great for understanding customer sentiment, but not everyone takes the time to leave a rating. That’s where implicit signals become invaluable. For example, if a caller hangs up mid-conversation or repeatedly asks the same question, it’s a clear sign something is wrong. Automated systems can also flag issues like hallucinations or formatting errors as they happen, without interrupting the flow of the conversation.
Human reviewers play a critical role in catching subtleties that automation might miss. For example, they can assess whether the AI's tone was appropriate during a sensitive interaction. However, manual reviews typically cover only 1%–4% of total calls. To make the most of this limited capacity, use AI-assisted tools to flag calls that need closer attention - like those with low satisfaction scores or compliance risks. This lets your team focus on the most important cases.
Keep detailed logs of every interaction. Record the caller's question, the AI's response, the context, the version of the prompt used, latency, and costs. These logs act as a replayable record for troubleshooting and debugging. To prevent any impact on live conversations, run automated consistency checks on these logs after the call ends. On average, each reviewer manually examines 4–8 calls per month, while AI tools extend coverage to the rest.
Focusing on High-Priority Issues First
With KPIs in place, focus on the feedback that has the biggest impact on performance. Not every piece of feedback needs immediate action. For instance, a single thumbs-down doesn’t mean you should overhaul your system. Instead, categorize feedback by its severity and set thresholds to separate recurring problems from isolated incidents. High-priority issues - like hallucinations or errors that occur more than 50 times - should be addressed immediately. Medium-priority issues, such as incomplete responses, can wait until clear patterns emerge.
To avoid chasing one-off anomalies, establish a rule: wait for 3 to 5 reports of the same issue before flagging it for action. Group feedback into categories like "hallucination", "wrong answer", "incomplete data", or "compliance violation", and rank these by how often they occur and their impact on your business. For example, if your AI is misquoting prices on 60 calls per week but only uses awkward phrasing on 5 calls, the pricing error should take priority.
Set up escalation triggers for high-stakes situations. Keywords like "emergency", "complaint", or "manager" can automatically flag calls for human review. In customer service, this might include billing disputes, cancellations, or legally required disclosures where errors carry a higher cost. By focusing your team’s efforts on these critical cases, you can make the most of your quality assurance resources.
Lastly, monitor the feedback-negative rate - the percentage of conversations that result in negative feedback - and track how it changes over time. If this rate doesn’t improve after several feedback cycles, it’s a sign that your categorization or thresholds might need adjusting. This metric provides a clear snapshot of how effective your feedback loop really is.
Building Safe and Scalable Feedback Systems
Once you've set up feedback collection and prioritization, the next step is to apply that feedback through safe and scalable updates. The challenge here isn't just improving your AI - it’s ensuring that updates don’t disrupt live operations or corrupt your system’s knowledge base. A single faulty update can ripple through your AI’s memory, leading to errors in future reasoning steps. That’s why it’s critical to treat your AI’s memory and logic like production data pipelines, complete with versioning, validation, and rollback mechanisms.
Protecting AI Memory and Knowledge During Updates
Your AI’s memory - whether working, episodic, or semantic - must be safeguarded during updates. Semantic memory, in particular, is sensitive to errors, as even small mistakes can distort all future reasoning.
To minimize risks, rely on staged rollout pipelines. Test all updates in isolation before deploying to a small percentage (5–10%) of live traffic. Monitor metrics closely, and be ready to roll back immediately if issues arise. For instance, staged rollouts and rollback strategies have been shown to significantly enhance accuracy in similar systems.
Version control is another essential practice. Treat AI memory, planning logic, and model checkpoints as immutable, timestamped artifacts. This allows you to quickly revert to earlier versions if problems occur. Incorporating validation gates into your deployment pipeline can block updates that fail to meet critical thresholds, such as latency, safety scores, or task success rates. Automated regression tests against known failure cases add another layer of protection. A particularly effective safety measure is the objective kernel - a read-only service that enforces your top-level business goals and safety rules, ensuring updates don’t cause unintended goal drift.
Managing Feedback at Scale
As the volume of calls and interactions grows, your feedback system must scale without creating bottlenecks. One way to achieve this is by separating the observer (data collection) from the executor (live operations). This prevents feedback loops from contaminating the system in real time.
Implicit signals, such as call abandonment rates or repeated questions, are invaluable when explicit feedback is limited. For example, Cursor’s Tab completion model processes implicit acceptance and rejection signals from 400 million daily requests, updating every 1.5 to 2 hours. This approach has resulted in 21% fewer suggestions and a 28% increase in acceptance rates.
For high call volumes, risk-tiered routing is essential. This system prioritizes human review for high-risk or low-confidence cases, flagged by triggers like keywords ("emergency", "complaint", or "manager"). Automating low-risk tasks ensures efficiency, while high-priority cases receive the attention they need. This is particularly important in service industries, where up to 85% of customers whose calls go unanswered don’t try again.
Another useful technique is shadow traffic validation. This involves testing new model versions or prompt templates with real-time data that doesn’t affect the user experience. By catching edge-case failures early, you can prevent them from reaching customers. Teams that adopt weekly retraining cycles often see quality improvements about 2.1× faster compared to those using monthly updates. By combining safe update practices with scalable feedback systems, your AI can stay aligned with business objectives while continually improving customer service.
Tools and Technologies for Feedback Loops
A well-built tech stack can transform feedback loops into a powerful advantage. To achieve this, your system should excel at capturing interactions, processing feedback efficiently, and implementing improvements without disrupting active operations. As Harrison Chase, CEO of LangChain, aptly explains:
"In software, the code documents the app; in AI, the traces do".
Core Tools for Processing Feedback
Orchestration frameworks like LangChain and AutoGen are crucial for managing agent logic and maintaining multi-turn context through tools like ConversationBufferMemory. Imagine a customer calling back about a previous issue - your system should recall the earlier interaction seamlessly, without requiring them to start from scratch.
Vector databases play a key role in storing and querying extensive feedback data. Technologies like Pinecone, Weaviate, and Chroma convert feedback into embeddings, making it possible to perform semantic searches and uncover patterns across thousands of interactions. For instance, a financial services company using vector databases to refine conversation strategies saw a 30% boost in engagement rates.
Observability platforms such as LangSmith and Langfuse provide comprehensive tracing for every decision made by AI agents. They track every LLM call, tool usage, and retrieval step. These platforms also enable automated evaluations using smaller models (e.g., GPT-4o-mini at $0.15 per 1M input tokens), which are 15× cheaper and 2–3× faster than GPT-4. For example, when Claude Code was enhanced with LangSmith Skills, its evaluation performance skyrocketed from 17% to 92%.
Tool Category Specific Technologies Primary Function Orchestration LangChain, AutoGen, CrewAI Managing agent logic and tool usage Vector Storage Pinecone, Weaviate, Chroma Semantic search through feedback storage Observability LangSmith, Langfuse Tracing, debugging, and scoring runs Memory ConversationBufferMemory Retaining multi-turn chat history
Before diving into complex evaluations, start by focusing on tracing - this serves as the "raw material" for improvement. For high-volume environments, evaluate a random sample (10–20%) of traces to keep API costs manageable. To further reduce expenses, use deterministic code-based checks for tasks like schema validation.
Now, let's take a closer look at how Answering Agent integrates these tools to deliver exceptional performance.
How Answering Agent Handles Feedback Loops
Answering Agent leverages orchestration, vector storage, and observability tools to maintain 99.93% call accuracy across 17,724+ scored interactions. By integrating tracing directly into its system, it captures reasoning chains and tool inputs automatically, eliminating the need for manual instrumentation. Real-time feedback allows the platform to identify and correct errors during live calls.
The architecture is designed to handle unlimited simultaneous calls without sacrificing performance. It achieves this by separating feedback collection from execution - feedback is gathered asynchronously, ensuring customer interactions remain smooth and uninterrupted. When implicit signals, such as repeated questions or phrases like "speak to a human", are identified, the system flags them for review and updates prompts for specific failure scenarios. These updates are rigorously validated in staging before being deployed to production, minimizing the risk of introducing new issues.
For businesses managing high call volumes, this approach has proven critical. Testing edge cases before deployment has reduced customer complaints by 80%. Answering Agent's feedback loop has also directly impacted business outcomes, with 20,375 offers pitched and 6,820 accepted, showcasing the tangible benefits of continuous improvement.
Measuring Results and Improving Over Time
Tracking Feedback Loop Performance
To gauge the success of your AI system, focus on three key metrics: negative feedback rate (the percentage of interactions with negative signals), resolution rate (how often issues are resolved without needing escalation), and repeat-contact rate (customers returning with the same unresolved issue). Ideally, these metrics should trend toward established benchmarks, such as CSAT >85%, FCR >70%, and AHT <5 minutes, as your system matures and improves.
While traditional manual QA typically reviews just 1–4% of calls, AI-driven feedback loops analyze 100% of interactions. This comprehensive analysis uncovers patterns that manual reviews might miss. Vik Chadha, Founder & CEO of Globalify, highlights the value of this approach:
"A well-run QA program improves CSAT by 15–25% within 6 months by catching coaching opportunities early and reinforcing good behaviors".
To ensure accurate measurement, internal QA scores must align closely with external CSAT scores. Additionally, keep the calibration variance between evaluators or AI scoring models below 5% to maintain consistency. Compliance adherence is non-negotiable - maintaining a 100% rate is essential to avoid legal risks.
These metrics provide actionable insights, helping you fine-tune your system while ensuring it stays aligned with your business objectives.
Keeping AI Aligned with Business Goals
Automated systems require safeguards to ensure updates don’t disrupt performance. It’s critical to avoid pushing automated prompt updates directly into production. Instead, test updates in a controlled staging environment using a set of known-good responses. As CallSphere Blog advises:
"A single thumbs-down should never trigger an automated system prompt change".
Updates should only be implemented after multiple corroborating reports identify the same issue. Employ automated alignment checks (also known as evals) to compare new prompt outputs against expected responses before deployment. Use statistical significance testing in A/B comparisons to confirm that changes genuinely enhance performance.
It’s also essential to review monitoring guidelines at least quarterly to ensure they reflect updates to products, scripts, or compliance requirements. For high-stakes scenarios - such as those involving hallucinations or financial disclosures - retain human-in-the-loop oversight to mitigate risks. This combination of automation and human review ensures your AI system evolves while staying reliable and effective.
Key Takeaways
Creating effective AI call feedback loops relies on a four-step process: collection, categorization, analysis, and action. This approach ensures your system evolves over time rather than plateauing at its initial performance level. As CallSphere puts it, "Deploying an AI agent is the beginning, not the end. Without a systematic way to collect, analyze, and act on user feedback, your agent's performance stagnates while user expectations grow". These steps are essential for improving AI call quality management.
One major improvement comes from moving away from manual sampling to analyzing high-volume interactions. Traditional QA processes typically review only 1% to 5% of calls, leaving many issues unnoticed. AI-powered feedback loops, on the other hand, analyze every single call, uncovering trends and patterns that manual reviews often miss.
Another game-changer is real-time intervention. AI systems can address issues like script deviations or compliance errors during the call itself, rather than waiting until after it ends. This immediate feedback helps both agents and AI improve on the spot. Maria Edington from Balto highlights this shift: "The future of QA is real-time - setting your agents up for success while they're on the call, not after it's over".
It's also important to look beyond explicit feedback like thumbs-up or thumbs-down ratings. Implicit signals, such as conversation abandonment, repeated questions, or escalation requests, provide deeper insights into user satisfaction. To maintain accuracy, you can set thresholds - such as requiring 3 to 5 similar reports before flagging an issue - and test automated updates in controlled environments before applying them broadly. This approach balances innovation with reliability.
Finally, a hybrid model combines the strengths of automation and human expertise. AI can handle scoring for the majority of interactions while flagging high-priority cases - like escalations, compliance issues, or highly frustrated customers - for human review. This ensures compliance and allows trained professionals to apply judgment in complex situations, achieving a balance between efficiency and accuracy.
FAQs
Which KPIs should I track first for my AI phone system?
To gauge how well your AI is performing, begin with key performance indicators (KPIs) that focus on both efficiency and customer satisfaction. Pay close attention to call accuracy and understanding - these show how effectively the AI handles customer inquiries.
Other critical metrics to track include:
- Customer satisfaction scores (CSAT): A direct measure of how happy users are with their experience.
- First-call resolution rate: The percentage of issues resolved during the first interaction.
- Call handling time: How long it takes to manage each call, balancing speed with quality.
If your system is designed to generate leads or schedule appointments, make sure to monitor lead conversion rates. These metrics will give you a clear picture of your system's strengths and areas for improvement.
How do I spot and reduce AI hallucinations on calls?
To make AI responses more reliable, you can use strategies like retrieval-augmented generation (RAG). This method improves factual accuracy by pulling in and verifying information from external sources. Another helpful approach is setting up feedback loops to evaluate and fine-tune responses, which can greatly reduce errors. Keeping an eye on accuracy metrics and leveraging real-time analytics can also help identify and fix problems as they arise. When these methods are used together, they create AI systems that are far more dependable and precise.
What’s the safest way to roll out prompt or knowledge updates?
To ensure safe and effective updates in AI call systems, it's crucial to follow a structured approach that minimizes errors and maintains system performance. Start by carefully designing updates with clear prompts and detailed instruction sets. Before deployment, conduct rigorous testing in controlled settings or with a limited number of calls to identify potential issues.
Once the updates are ready, roll them out gradually. Keep a close eye on key metrics like accuracy and escalation rates to ensure the system remains stable. Use feedback loops to gather insights and make adjustments as needed, fostering continuous improvement in the system's performance.
Related Blog Posts
Ready to see it handle your calls?
Book a walkthrough, or hear a short sample call first.
Related Articles
AI Answering Service for HVAC: Stop Missing High-Ticket Emergency Calls
Discover how an AI answering service for HVAC handles seasonal spikes, books high-ticket emergency calls 24/7, and stops wasting your marketing spend.
How an AI Receptionist Keeps Auto Detailing Shops Booked While Buffers Are Spinning
Discover how an AI receptionist for auto detailing captures high-margin ceramic coatings, handles vehicle-size pricing, and books appointments 24/7.
AI Email for Customer Follow-Up
Bring customer emails into Answering Agent. Learn what AI Email can handle, when it routes work to your team, and how to turn it on for your locations.